X-Foresight: A Joint Vision-Action Causal Forecasting Network via Predictive World Modeling
Why predictive world modeling for VLA?
Physical world knowledge resides mainly in videos. Equipping Vision-Language-Action (VLA) models with that knowledge is fundamental for safe, generalizable planning, and predictive world modeling extracts it by forecasting future video from past observations. But naive next-frame prediction faces two challenges: video tokens are inherently low-entropy and redundant, so prediction easily collapses to trivial extrapolation; and instantaneous dynamics demand dense frames while long-term causality unfolds over long, variable horizons that dense prediction cannot efficiently cover.
X-Foresight integrates a predictive world model directly into the VLA architecture, jointly learning world modeling and real-time action control. Its core is a long-horizon chunk-wise auto-regressive strategy: predicting across semantically distant chunks escapes trivial extrapolation, while dense intra-chunk frames capture instantaneous dynamics and sparse inter-chunk transitions capture long-term causality — at tractable training cost. A curriculum schedule progressively extends prediction horizons to stabilize long-horizon training; temporal importance sampling concentrates supervision on safety-critical chunks; and a diffusion-based multi-view renderer restores photorealistic appearance. X-Foresight significantly outperforms VLA baselines in planning while maintaining strong generative fidelity.
Contributions
- We introduce a long-horizon chunk-wise auto-regressive strategy that leverages extended future horizons for world modeling. This design both mitigates the collapse of world-knowledge learning under naive next-frame prediction and resolves the temporal dilemma: dense intra-chunk frames allow the model to capture instantaneous dynamics, while long-horizon chunk-level prediction promotes the learning of broader world causality.
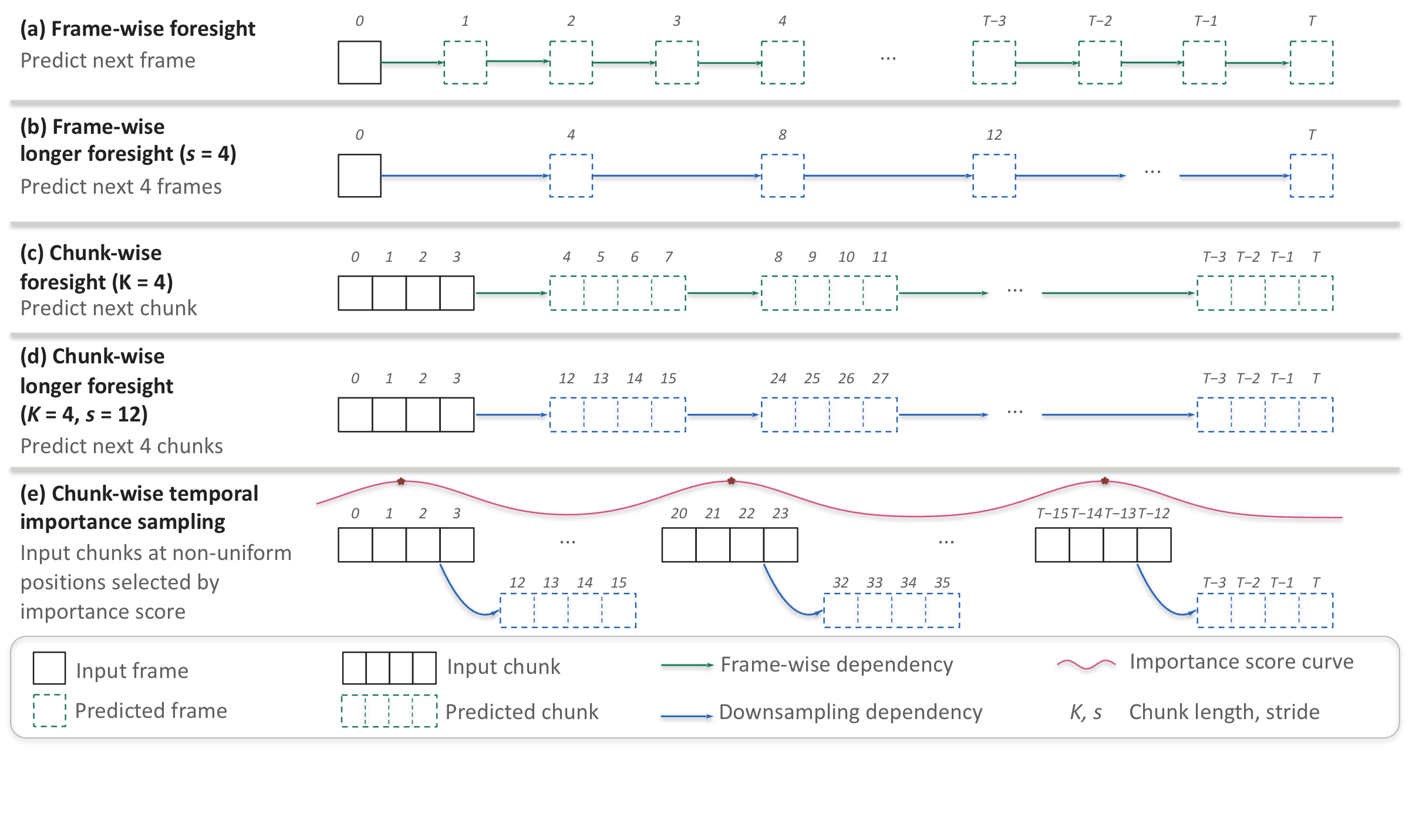
- To improve long-horizon forecasting stability and enhance policy robustness, we exploit a curriculum-based learning strategy, starting with short-horizon prediction across chunks and gradually extending to longer strides.
- We adopt temporal importance sampling, a hybrid sampling mechanism that accounts for uneven contributions of future frames to world-knowledge learning, combining random selection with importance-weighted focus on critical temporal transitions.
- The proposed method can acquire high-fidelity multi-view future images. Integration of a diffusion-based renderer into the auto-regressive pipeline is developed to reconstruct photorealistic surround-view details.
Industry-scale multi-camera driving
We built an industry-level dataset with approximately 280,000 hours of in-house driving data — 34 million clips up to 30 s each, tokenized into 13.8 T tokens. A 7-camera surround-view rig (front fisheye, front narrow, left/right front, left/right rear, rear) provides 360° coverage. Streams are stored at 12 Hz and downsampled to 4 Hz for training, balancing motion fidelity against tractable sequence length.

Large Drive Model + Vision Renderer
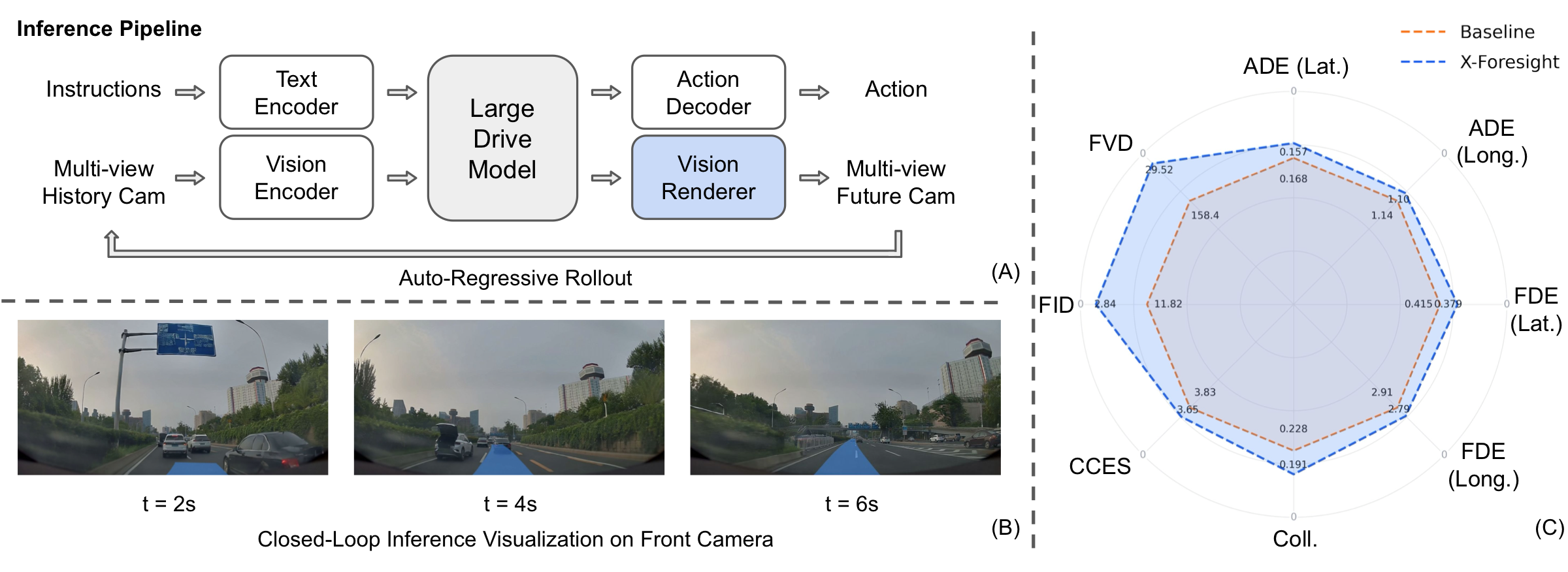
X-Foresight consists of two modules. The Large Drive Model (LDM) is an auto-regressive transformer that consumes multi-view observations, language, and ego-state, and predicts three targets at every step: ego actions for real-time control, a bird's-eye-view scene plot, and per-camera latent tokens summarizing the future appearance from each viewpoint. The Vision Renderer is a diffusion-based decoder whose rendered frames are fed back into the LDM as fresh observations, closing the auto-regressive loop.
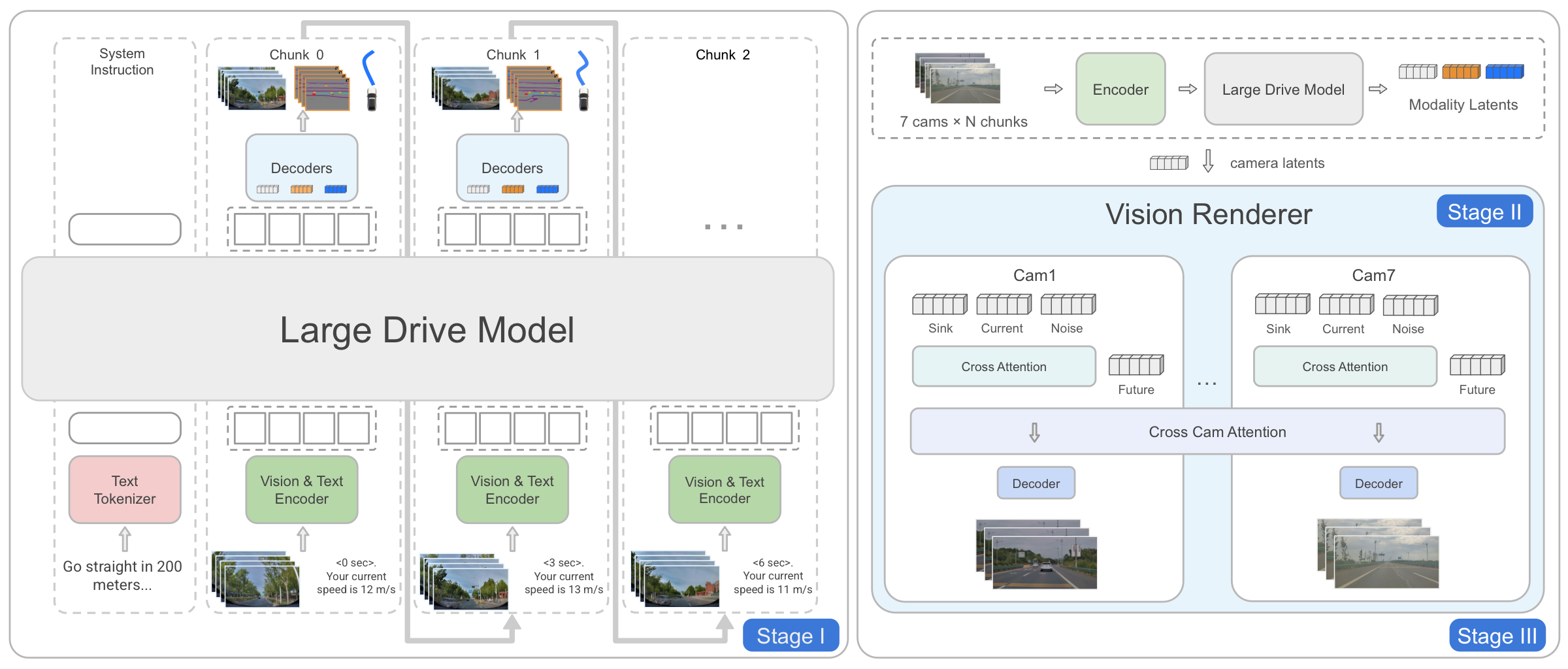
Large Drive Model
Multi-modal prompt: a global system prompt followed by temporal chunks
[ li, Oi, Ai, Qi ] — horizon text,
multi-view ViT tokens, ego state, query tokens that trigger future-variable prediction.
Trained end-to-end under teacher forcing on action, camera, and BEV losses.
Vision Renderer
A DiT video generator with rectified-flow objective, built atop X-World's view-temporal attention and a 3D causal VAE. The renderer is conditioned only on the LDM's camera tokens (no action shortcut), restoring photorealistic detail while remaining controlled by the LDM's latent imagination.
Chunk-wise foresight, not adjacent-frame guessing
Frame-wise prediction provides only a weak learning signal — adjacent camera frames differ only marginally over short intervals, and the model collapses into trivial extrapolation. Aggressive temporal downsampling helps the horizon but loses the motion cues needed for trajectory prediction.
Chunk-wise foresight preserves short-term structure inside each 1-second chunk while requiring the model to predict a longer segment of future evolution at every auto-regressive step. Increasing the stride between chunks (longer foresight) extends the prediction horizon at no extra compute, and temporal importance sampling directs the limited budget to safety-critical maneuvers.
Closed-loop rollouts
Each clip below is a full closed-loop rollout: at every step the LDM emits the next ego action and one second of multi-view latent tokens, which the Vision Renderer decodes into seven surround-view frames before the next prediction. Select an example to view.
Production-scale headline
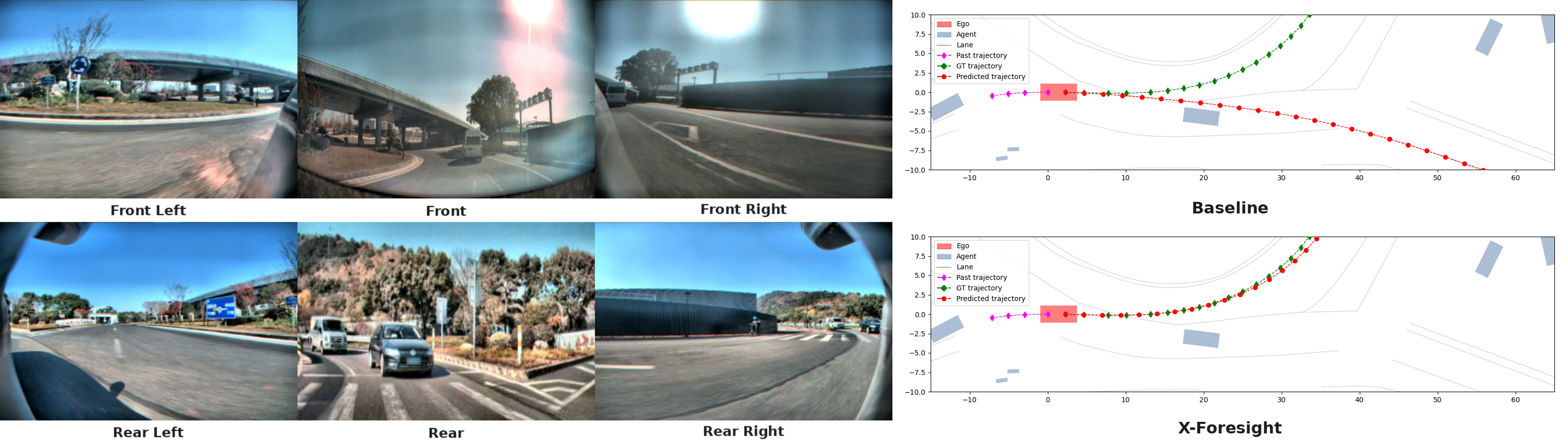
The full X-Foresight model (H=21 with CLEF and TIS, trained on 1024 GPUs) is compared against a baseline trained at the same scale. Lateral and longitudinal ADE improve by 6.4 % and 3.6 % (0.1675 → 0.1567 lat; 1.1387 → 1.0982 long), and lateral and longitudinal FDE by 8.8 % and 4.1 % (0.4153 → 0.3789 lat; 2.9117 → 2.7924 long). Collision rate drops from 0.228 % to 0.191 %, a 16.2 % relative reduction. All four CCES categories improve — Safety by 9.1 %, Compliance by 8.2 %, Comfort by 1.0 %, and Efficiency by 0.4 % — driving the aggregate Total from 3.8296 to 3.6535, a 4.6 % relative reduction. Gains concentrate in Safety and Compliance, consistent with the central claim that long-horizon world-causality supervision improves safety-critical decision quality.
| Method | ADE ↓ | FDE ↓ | Coll. ↓ | Compl. ↓ | Comfort ↓ | Eff. ↓ | Safety ↓ | Total ↓ | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Lat. | Long. | Lat. | Long. | |||||||
| Baseline | 0.1675 | 1.1387 | 0.4153 | 2.9117 | 0.228 | 0.9483 | 0.9505 | 0.9867 | 0.9441 | 3.8296 |
| X-Foresight | 0.1567 | 1.0982 | 0.3789 | 2.7924 | 0.191 | 0.8708 | 0.9413 | 0.9831 | 0.8583 | 3.6535 |
Qualitative comparisons
Two scenarios illustrate how the aggregate gain manifests qualitatively — both turning on correct action toward events that lie ahead in space or in time, the central capability the reactive baseline lacks by construction.
Effect of training-time horizon H
| Horizon | ADE ↓ | FDE ↓ | Coll. ↓ | Compl. ↓ | Comfort ↓ | Eff. ↓ | Safety ↓ | Total ↓ | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Lat. | Long. | Lat. | Long. | |||||||
| H = 1 | 0.1923 | 1.2409 | 0.4881 | 3.1935 | 0.263 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 4.0000 |
| H = 6 | 0.1864 | 1.2196 | 0.4691 | 3.1178 | 0.262 | 0.9756 | 0.9880 | 0.9833 | 0.9927 | 3.9396 |
| H = 21 | 0.1810 | 1.2110 | 0.4571 | 3.0988 | 0.245 | 0.9533 | 1.0416 | 1.0094 | 0.9481 | 3.9524 |
Ablating CL · CLEF · TIS
| Method | ADE ↓ | FDE ↓ | Coll. ↓ | Compl. ↓ | Comfort ↓ | Eff. ↓ | Safety ↓ | Total ↓ | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Lat. | Long. | Lat. | Long. | |||||||
| Cont. H=6 | 0.1741 | 1.1807 | 0.4344 | 3.0087 | 0.270 | 0.9302 | 1.0515 | 0.9980 | 0.9726 | 3.9523 |
| + H=21, CL | 0.1718 | 1.1671 | 0.4277 | 2.9856 | 0.238 | 0.9326 | 1.0106 | 1.0003 | 0.9310 | 3.8745 |
| + H=21, CLEF | 0.1692 | 1.1571 | 0.4181 | 2.9421 | 0.230 | 0.9320 | 1.0076 | 0.9951 | 0.9387 | 3.8734 |
| + H=21, TIS | 0.1696 | 1.1578 | 0.4195 | 2.9413 | 0.216 | 0.9187 | 1.0043 | 0.9953 | 0.9264 | 3.8447 |
Vision Renderer fidelity

| Method | FID ↓ | FVD ↓ | ||
|---|---|---|---|---|
| 1 s | 6 s | 1 s | 6 s | |
| Camera Latent Decoder | 10.97 | 11.82 | 135.56 | 158.39 |
| Vision Renderer | 1.51 | 2.84 | 11.28 | 29.52 |
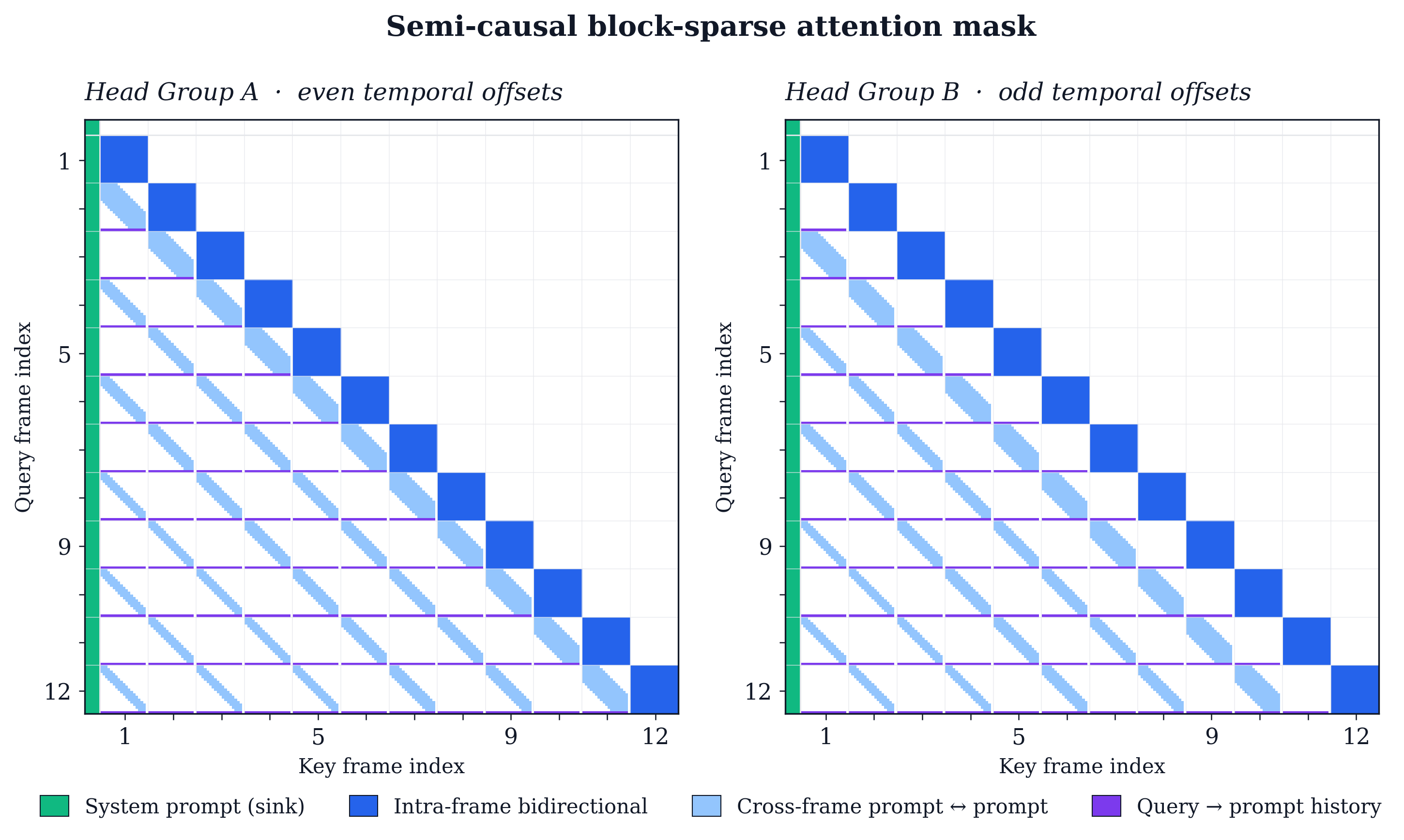
Training throughput
| Attention implementation | Per-step time (s) ↓ | Speedup ↑ |
|---|---|---|
| FlashAttention-2 | 24.50 | 1.00× |
| Block Sparse Attention w/ our mask | 15.40 | 1.59× |
Paper, citation, contributors
The technical report is available on arXiv. If X-Foresight informs your research, please cite us:
@techreport{xforesight2026,
title = {X-Foresight: A Joint Vision-Action Causal Forecasting Network via Predictive World Modeling},
author = {{PWM Team}},
year = {2026},
institution = {XPeng Inc.},
url = {https://arxiv.org/abs/2605.24892}
}
Contributors
- Advisors
- Yu Zhang, Xianming Liu
- Project Lead
- Zhuangzhuang Ding, Pengkun Zheng
- Core Contributors (alphabetical)
- Baolu Li, Jingyu Qian, Rui Guo, Yilun Chen
- Contributors
- Hanpeng Liu, Yuan Lin, Junhong Zhou, Ruixin Liu, Willow Yang, Yutong Zheng, Zhenli Zhang
- Technical Program Manager
- Tenglong (Victor) Gu